OCR چیست و چطور تحول خدمات اداری را رقم میزند؟
فناوری OCR یا Optical Character Recognition (تشخیص نوری کاراکترها) در سالهای اخیر یکی از ارکان تحول دیجیتال در سازمانها شده است. این فناوری به سیستمها امکان میدهد متون موجود در تصاویر، اسکنها، PDFها و عکسهای مدارک را به متن دیجیتالی قابلجستوجو و ویراستنی تبدیل کنند. با رشد نیاز به حذف فرایندهای کاغذی، کاهش خطاهای انسانی و افزایش سرعت پردازش دادهها، OCR در سال ۲۰۲۵ دیگر فقط یک ابزار فناورانه نیست، بلکه یک مزیت رقابتی است.
این تصویر احتمالاً برای شما هم آشناست: کارمندی که پشت میز، خسته از ورود شماره ملیها یا پرکردن اطلاعات بیمهای، هر چند دقیقه درنگ میکند تا اشتباهاتش را تصحیح کند. تا همین چندی پیش این تصویر سکانسی تکراری در تمامی ادارهها، سازمانها، بانکها و … بود و ورود اطلاعات در سازمانها مساوی بود با کوهی از فرمهای کاغذی، ساعتها تایپ دستی و خطاهای ریز و درشتی که گاهی پیامدهای بزرگی داشتند؛ اما همانطور که انقلابهای فناورانه همیشه از جایی کوچک و بیصدا شروع میشوند، فناوری OCR آرامآرام راه خود را باز کرد. این ابزار فقط وعده سرعت و دقت نمیداد، بلکه الگوی کارکردن ما با دادهها را برای همیشه تغییر داد.
این روزها OCR به یکی از ارکان اصلی تحول دیجیتال در دنیا تبدیل شده است. این فناوری امکان میدهد متون موجود در تصویرها، اسکنها و PDFها به دادههای دیجیتالی قابل جستوجو و پردازش تبدیل شوند. با رشد نیاز به حذف فرایندهای کاغذی، کاهش خطای انسانی و افزایش سرعت پردازش اطلاعات، OCR در سال ۲۰۲۵ دیگر فقط یک ابزار فناورانه نیست، بلکه به مزیت رقابتی سازمانها تبدیل شده است. طبق گزارش Grand View Research، اندازه بازار جهانی OCR در سال ۲۰۲۳ به ۱۲.۵۶میلیارد دلار رسید و پیشبینی میشود تا ۲۰۳۰ با رشد سالانه ۱۴.۸ درصد به بیش از ۳۰میلیارد دلار برسد. این رشد بیش از هر چیز به ادغام OCR با فناوریهای انقلابی مانند هوش مصنوعی، یادگیری ماشین و اتوماسیون فرآیندها مدیون است و در حوزههایی مانند بانکداری، بیمه، فینتک، آموزش، سلامت و تجارت الکترونیک تغییرات بنیادین ایجاد کردهاند.
تاریخچه کوتاه OCR
شروع OCR به نیمه قرن بیستم و به زمانی باز میگردد که نخستین ماشینهای مکانیکی برای کمک به افراد نابینا توسعه یافتند. در دهه ۱۹۵۰ ریموند کرتزویل، پایهگذار OCR نوین، پروژههایی مانند ماشین «GISMO» را آغاز کرد. در آن زمان این ماشینها صرفاً میتوانستند حروف چاپی را تشخیص دهند، آنهم با فونتهای محدود و یکنواخت.
در دهه ۱۹۸۰ و ۱۹۹۰ میلادی الگوریتمهای تطبیق الگو (Pattern Matching) و دستهبندی آماری وارد کار شدند. این تکنیکها دقت OCR را به سطح قابلقبولی (تا حدود ۹۰ درصد) رساندند و امکان خواندن متون چاپی عمومیتر را فراهم کردند. همزمان شرکتهایی مانند ABBYY و Adobe ابزارهای ابتدایی تبدیل PDF به متن را به بازار وارد کردند.
با ورود قرن بیستویکم OCR به مرحلهای جدید وارد شد. استفاده از شبکههای عصبی کانولوشنی (CNN) و یادگیری عمیق (Deep Learning) از سال ۲۰۱۲ بهبعد، خصوصاً با ظهور دیتاستهایی مانند IAM و MNIST، دقت شناسایی کاراکتر به بالای ۹۷ درصد رسید. ترکیب OCR با مدلهای زبان (Language Models) امکان اصلاح املا و بازسازی ساختار سند را فراهم کرد.
از ۲۰۲۰ بهبعد، مدلهای Vision Transformer یا ViT و GPT به OCR اضافه شدند. این ترکیب کمکى کرد تا سیستمهای مدرن، نهتنها کاراکترها را شناسایی کنند، بتوانند زبان سند را تشخیص دهند، عبارتهای اشتباه را اصلاح کنند، بافت معنایی را بفهمند و حتی بهصورت چندزبانه یا بر بستر مرورگر عمل کنند.
امروزه OCR فقط یک ابزار نیست، بلکه بخشی از زیرساخت هوشمند استخراج داده، تحلیل اسناد و اتوماسیون تصمیمگیری در صنایع متنوع بهویژه فینتک و رگتک است.

OCR چگونه کار میکند؟
در قلب هر سامانه OCR زنجیرهای از پردازشهای تصویر، تحلیل آماری، یادگیری ماشین و منطق زبانی قرار دارد. هدف این فرایند تبدیل یک تصویر خام به دادهای ساختیافته، قابلتحلیل و قابلاستفاده در سیستمهای سازمانی است. این زنجیره معمولاً در پنج مرحله کلیدی اجرا میشود:
- پیشپردازش (Preprocessing): در این مرحله کیفیت تصویر بهینه میشود. تکنیکهایی مانند حذف نویز، تصحیح زاویه (deskew)، افزایش کنتراست، باینریسازی تصویر (thresholding) و عادیسازی روشنایی مقدمات تبدیل دقیقتر تصویر به متن را فراهم میکنند.
- تشخیص ناحیه متن (Text Detection): الگوریتمهای بینایی ماشین نواحی حاوی متن را از دیگر عنصرها، ازجمله لوگو، نمودار یا جدول، تشخیص میدهند. این مرحله ورودی مرحله بعدی، یعنی بخشبندی، را بهدقت محدود میکند.
- بخشبندی خطوط و حروف (Segmentation): متن شناساییشده به خطوط، کلمهها و سپس حروف منفرد تقسیم میشود. در زبان فارسی، بهدلیل چسبندگی کاراکترها، این مرحله بهمراتب پیچیدهتر از زبانهای لاتین است و درنتیجه، به الگوریتمهای سفارشی نیاز دارد.
- تشخیص کاراکتر (Character Recognition): هر کاراکتر، با استفاده از شبکههای عصبی کانولوشنی (CNN)، مدلهای CTC یا Vision Transformer، شناسایی و به کد معادل متنی آن تبدیل میشود. برخی موتورهای پیشرفته از مدلهای زبانی، مانند BERT یا GPT، نیز برای پیشبینی هوشمند کاراکترها در بستر جمله استفاده میکنند.
- پسپردازش و تولید خروجی: در این مرحله متن خام اصلاح میشود. اصلاحات این مرحله تصحیح غلطهای املایی، تشخیص زبان، بازسازی ساختار سند، مثلاً فاکتورها یا فرمها، و تولید خروجیهای استاندارد مانند PDF قابلجستوجو، فایلهای متنی ساختاریافته (CSV یا JSON) یا اتصال مستقیم به پایگاه داده را شامل است.
OCRهای مدرن، بهویژه در فضاهای ابری یا مدلهای سفارشیشده، میتوانند این زنجیره را در کمتر از یک ثانیه روی هر سند اجرا کنند. درواقع، OCR، نهتنها تصویری از متن را به فایل متنی تبدیل میکند، میتواند سند را «بفهمد»، بخشبندی کند، دستهبندی کند و بهصورت آماده برای تحلیل یا تطبیق در فرایندهای سازمانی تحویل دهد.
گامهای پیادهسازی در یک سازمان (چکلیست عملی)
استفاده از OCR در سازمانها صرفاً به خرید یک سرویس ختم نمیشود. برای رسیدن به دقت بالا، بهرهوری بیشتر و حداکثر تطابق با الزامات فنی و قانونی، سازمانها باید یک مسیر پیادهسازی را مرحلهبهمرحله طی کنند. این مسیر انتخاب منابع داده مناسب، یکپارچهسازی فنی، تضمین امنیت دادهها و پایش دقت سیستم را در بر میگیرد. این جدول مهمترین مرحلههای پیادهسازی OCR در یک سازمان را مرور کرده است:
| مرحله | عمل کلیدی |
| انتخاب دیتاست | استفاده از اسناد واقعی شرکت برای فاینتیون مدل OCR |
| پیشپردازش | استقرار فیلترهای خودکار در لایه API |
| یکپارچهسازی | اتصال OCR به سیستمهای داخلی ERP/CRM با Webhook |
| ممیزی امنیت | رمزنگاری REST، ذخیرهسازی داخلی یا درونمرزی |
| مانیتورینگ دقت | استفاده از برچسبگذاری انسانی در تست A/B |
پس از پیادهسازی بهتر است بهصورت دورهای عملکرد OCR پایش شود؛ همینطور مدلها با دادههای جدید بهروزرسانی و تجربه کاربران داخلی یا مشتریان نهایی ارزیابی شود؛ همچنین در صورت استفاده از OCR در بخشهایی مانند KYC یا تحلیل اسناد مالی، ارزیابی ریسک و انطباق قانونی باید بهصورت مداوم بخشی از فرایند باشد.
مزایای کلیدی برای فینتک و بانکداری
در فضای رقابتی خدمات مالی و بانکی سرعت، دقت، انطباق قانونی و تجربه کاربری از مهمترین عوامل موفقیت هستند. فناوری OCR، با خودکارسازی مرحلههای پرزحمت ورود اطلاعات و تحلیل اسناد، نقش چشمگیری در ارتقای این شاخصها بازی میکند. بهرهگیری از OCR، بهویژه، در حوزههایی مانند احراز هویت، افتتاح حساب، پرداخت تسهیلات و پردازش چک یا قبض، میتواند اثربخشی عملیاتی را بهطور چشمگیری افزایش دهد.
مزیتهای برجسته استفاده از OCR از در صنعتهای مختلف از این قرار است:[
- کاهش خطای ورود داده تا ۹۰ درصد: ورود دستی اطلاعات از کارت ملی، شناسنامه یا قبض یکی از رایجترین منابع خطاست. OCR، با حذف این مرحله، دقت را افزایش و نیاز به اصلاح داده را کاهش میدهد.
- صرفهجویی زمانی تا ۷۰ درصد در فرایندهای پرکار: در عملیاتی مانند ثبتنام کاربران، بررسی مدارک تسهیلات یا تحلیل صورتحسابها، OCR میتواند زمان انجامشدن کار را از چند دقیقه به چند ثانیه کاهش دهد.
- انطباق با قوانین AML ،GDPR و الزامات بانک مرکزی: با OCR، اطلاعات کاربران بهصورت ساختاریافته ذخیره میشود، امکان ثبت لاگ وجود دارد و زیرساخت امنیتی برای حفظ اطلاعات شخصی فراهم میشود.
- افزایش رضایت مشتری و بهبود تجربه کاربری: با استفاده از فناوری OCR کاربران نیاز ندارند فرمهای طولانی را پر کنند یا عکس مدارک را چندبار بارگذاری کنند؛ فرایند احراز هویت یا ثبتنام فقط با یک تصویر تکمیل میشود.
این مزایا، نهفقط از هزینههای عملیاتی و ریسکهای انسانی میکاهد، بلکه توان رقابتی سازمانها را در ارائه خدمات سریع، دقیق و امن به مشتریان افزایش میدهد؛ همچنین استفاده هوشمندانه از OCR میتواند راه را برای استقرار مدلهای پیشرفتهتر، مانند KYC یکپارچه، اتوماسیون مالی و تحلیل رفتار مشتری، باز کند.

مقایسه سرویسهای پیشتاز OCR در ۲۰۲۵
با پیشرفت فناوریهای مبتنی بر یادگیری ماشین و هوش مصنوعی استفاده از OCR در حوزههایی مانند احراز هویت، پردازش سند و اتوماسیون مالی بهشدت گسترش یافته است و سرویسهای مختلفی در سطح بینالمللی و بومی در حال رقابت با یکدیگر هستند. هنگام انتخاب سرویس OCR چند شاخص کلیدی اهمیت بالایی دارند که باید به آنها توجه کرد؛ پشتیبانی از زبان فارسی، سرعت پردازش، دقت شناسایی زنده (Liveness) و مدل قیمتگذاری.
این جدول چهار سرویس پیشرو از منظر این معیارها با هم مقایسه میکند:
| سرویس | پشتیبانی فارسی | زمان پاسخ (برای ۱ صفحه) | دقت Liveness* |
| جیبیت OCR | بله | ۰٫۸ ثانیه | ۹۸ درصد |
| Google Document AI | خیر | ۱ ثانیه | ۹۷ درصد |
| Azure Document Intelligence | خیر (RTL محدود) | ۱٫۲ ثانیه | ۹۶ درصد |
| ABBYY Vantage 2.6 | خیر | ۰٫۹ ثانیه | ۹۷ درصد |
برتری جیبیت در پشتیبانی کامل از زبان فارسی، زمان پاسخ پایین و قیمت رقابتی آن را به گزینهای مناسب برای کسبوکارهای ایرانی تبدیل کرده است، بهویژه آنها که به انطباق با قوانین داخلی (مانند نگهداشت داده در کشور) نیاز دارند؛ درمقابل، سرویسهای بینالمللی مانند Google و Azure با قدرت پردازشی بالا و ادغامپذیری جهانی خود برای شرکتهای چندملیتی جذابترند، اما در پردازش اسناد فارسی و پشتیبانی بومی ضعف دارند.
درنهایت، انتخاب میان این سرویسها باید براساس نیاز سازمان، حساسیت دادهها، سطح بومیسازی موردانتظار و بودجه انجام شود.
چالشهای ویژه OCR فارسی و راهحلها
درحالیکه بسیاری از موتورهای OCR برای زبانهای لاتین و راستبهچپ محدود طراحی شدهاند، زبان فارسی ویژگیهای منحصربهفردی دارد که چالشهای چشمگیری در مسیر پردازش نوری کاراکترها ایجاد میکند. ساختار خط فارسی، نحوه اتصال حروف، نقطهگذاری، وجود دستنویسهای متنوع و حساسیتهای قانونی مربوط به اطلاعات هویتی به راهحلهای بومیسازیشده و مدلهای بهدقتآموزشدیده نیاز دارد.
این جدول سه چالش اساسی زبان فارسی در OCR و راهحلهای جیبیت برای غلبه بر آنها را آورده است:
| چالش | چرایی | راهحل جیبیت |
| دیتاست محدود برای دستنویس | تنوع بالا در خط، نقطهگذاری ب، ت، ث و سبک نوشتار | آموزش (fine-tune) مدل ViT روی بیش از دومیلیون سند فارسی با برچسبگذاری دقیق |
| تفکیک دشوار حروف چسبیده | اتصال بصری میان کاراکترها در اکثر فونتهای فارسی | استفاده از لایه زبان طبیعی و پیشبینی واژه براساس بافت جمله برای بازسازی کلمه |
| الزامات سختگیرانه حریم خصوصی | نیاز به نگهداری داده هویتی داخل کشور و پایش دسترسیها | استقرار بهصورت On-Prem یا Cloud اختصاصی، با زیرساخت ذخیرهسازی در ایران و رمزنگاری سطح بالا |
حل این چالشها، نهفقط دقت OCR فارسی را افزایش میدهد، امکان استفاده از آن را در سرویسهای حساس، مانند KYC، استعلام هویتی و پردازش فرمهای بانکی، فراهم میکند. جیبیت، با تمرکز بر توسعه مدلهای اختصاصی برای زبان فارسی، توانسته است به دقت و پایداری بالایی در پردازش انواع اسناد چاپی و نیمهدستی دست یابد؛ این ویژگی در سرویسهای بینالمللی بهسختی یافت میشود.
چشمانداز OCR و ۴ ترند برتر ۲۰۲۵
درحالیکه OCR در یک دهه گذشته از یک فناوری ساده به ابزاری حیاتی در اتوماسیون سازمانی تبدیل شده است، احتمالاً در ماههای پیش رو موج جدیدی از نوآوریها را شاهد خواهیم بود که مرزهای قابلیتهای OCR را گسترش میدهند. ترکیب OCR با مدلهای مولد مبتنی بر هوش مصنوعی، اتوماسیون کامل فرایندها و فناوریهای حفظ حریم خصوصی، این حوزه را به یکی از پیشرانهای تحول دیجیتال تبدیل کرده است.
چهار ترند اصلی OCR در سال جاری و آینده از این قرار است:
- Gen-AI OCR یا OCR مبتنی بر هوش مصنوعی مولد: مدلهای مولدی مانند GPT به OCR قدرت میدهند تا فیلدهای ناقص را تکمیل، ساختار اسناد را بازسازی و حتی اطلاعات زمینهای را پیشبینی کند. این قابلیت، بهویژه، در پردازش فرمهای ناقص، فاکتورهای غیررسمی یا اسناد تاریخی بسیار مفید است.
- هایپراتوماسیون (Hyperautomation): ادغام OCR با RPA (اتوماسیون روباتیک فرایندها)، سیستمهای مدیریت فرایند (BPM) و ابزارهای تحلیل فرایند (Process Mining) کمک میکند کل مسیر پردازش، from scan to action، بدون دخالت انسانی و با نظارت کامل انجام شود.
- حریم خصوصی پیشفرض با Edge OCR: انجامدادن پردازش OCR روی دستگاه یا در لبه شبکه (Edge Computing) بهجای فضای ابری، امنیت داده را بهشکل چشمگیری افزایش میدهد؛ بههمین دلیل، برای صنایع حساس، مانند بانک، بیمه یا سلامت، راهحل مناسبی ارائه میکند.
- Blockchain OCR: استفاده از بلاکچین برای ثبت هش اسناد OCRشده امکان تأیید اصالت اسناد را فراهم میکند و از دستکاری، جعل یا حذف بیمجوز دادهها جلوگیری میکند. این ویژگی در حوزههایی مانند اسناد قانونی، مالی و احراز هویت دیجیتال ارزش بالایی دارد.
پیشبینی میشود تا سال ۲۰۳۰ بیش از ۸۰ درصد از سیستمهای OCR پیشرفته بهنوعی از Gen-AI یا پردازش غیرمتمرکز بهرهمند شوند. کسبوکارهایی که از حالا به این روندها مجهز شوند، نهتنها از نظر سرعت و دقت، از نظر انطباق قانونی، امنیت اطلاعات و تجربه مشتری نیز بر رقبا پیشی خواهند گرفت.
نتیجهگیری
در چشمانداز ۲۰۲۵، OCR نهفقط ابزار تبدیل تصویر به متن، بلکه بخش مهمی از زنجیرهٔ احراز هویت دیجیتال، اتوماسیون اداری، و انطباق با مقررات شده است. با گسترش استفاده از مدلهای هوش مصنوعی، سرویسهایی مثل جیبیت OCR، بستری امن، دقیق و مقیاسپذیر برای استخراج اطلاعات از اسناد فارسی فراهم کردهاند.
اگر بهدنبال کاهش هزینه، افزایش سرعت پردازش، و بهبود تجربه کاربر هستید، همین حالا با ثبتنام رایگان، سرویس OCR جیبیت را امتحان کنید.

پرسشهای متداول (FAQ)
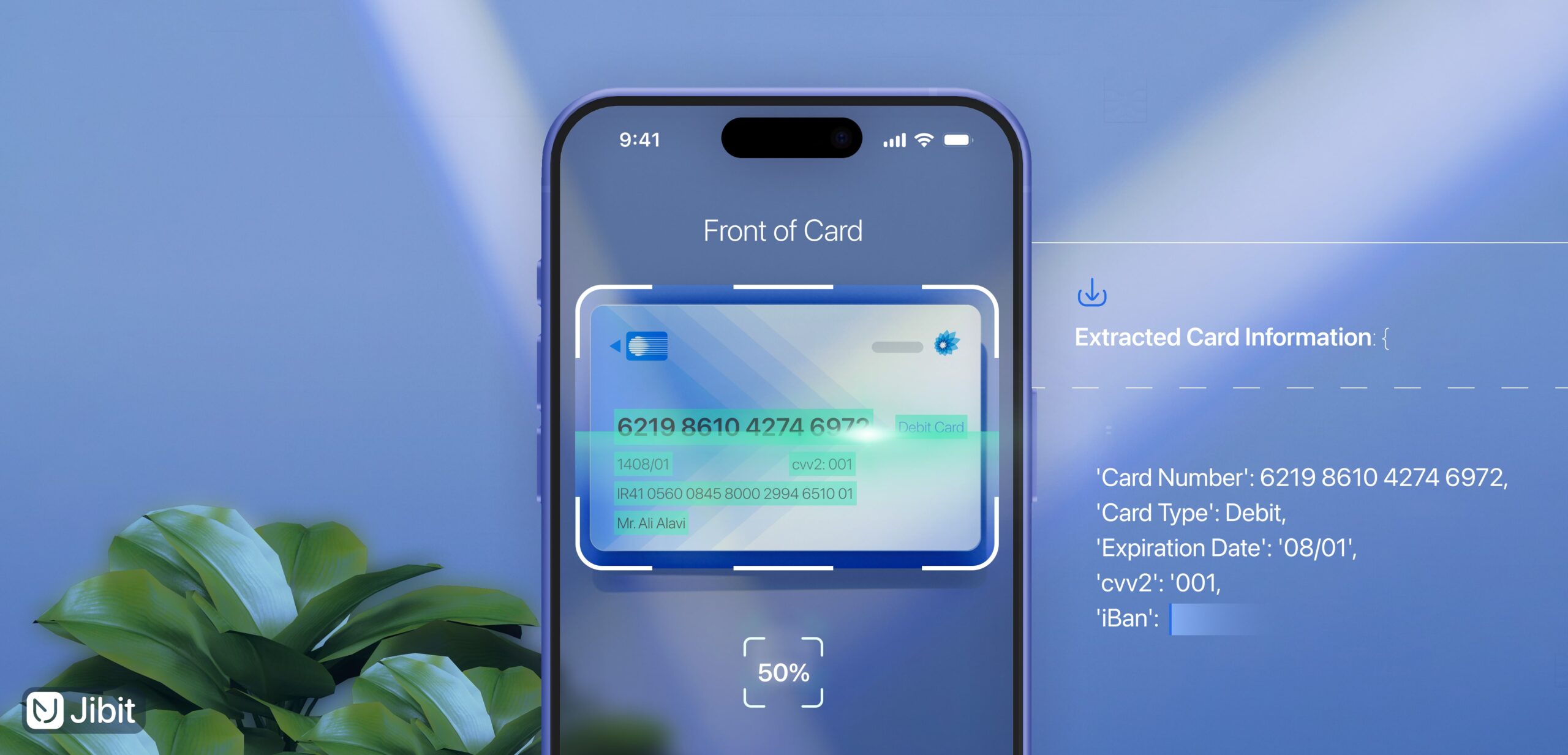
اسکن صرفاً یک تصویر دیجیتال از سند را ذخیره میکند، یعنی خروجی آن یک فایل تصویری است که قابل جستوجو، ویرایش یا تحلیل نیست، اما OCR، با استفاده از الگوریتمهای بینایی ماشین، متن موجود در آن تصویر را شناسایی، استخراج و به یک فایل متنی قابلپردازش (مانند JSON ،PDF جستوجوپذیر یا CSV) تبدیل میکند؛ بهعبارت ساده، اسکن فقط تصویربرداری است، ولی OCR «درک محتوای نوشتاری» همان تصویر است.
دقت OCR روی موبایل به کیفیت دوربین، شرایط نوری، فونت سند و الگوریتم پردازش بستگی دارد. در حالت استاندارد (رزولوشن ۱۰۸۰p و نور مناسب)، SDK موبایلی جیبیت توانسته است دقتی بالای ۹۶ درصد را برای اسناد چاپی ثبت کند؛ همچنین ویژگیهایی مانند تشخیص زنده چهره (Liveness) و پسپردازش زبانی باعث میشوند نتیجه نهایی از نظر معنایی نیز دقیقتر باشد، حتی اگر بخشی از تصویر ناخوانا باشد.
تا حد زیادی بله، بهشرط استفاده از موتور مناسب. زبان فارسی بهدلیل ساختار خاص حروف چسبنده و تنوع نقطهگذاری، در مقایسه با زبانهایی مانند انگلیسی، پردازش سختتری دارد؛ بااینحال نسخه جدید موتور OCR جیبیت که روی دیتاست اختصاصی دومیلیون سند فارسی آموزش دیده توانسته است به دقتی نزدیک به ۹۵ درصد برای متون چاپی و حدود ۸۸ درصد برای دستنویسها برسد که در سطح استاندارد بینالمللی بسیار قابلقبول است.
جیبیت برای سازمانها و توسعهدهندگان، پلن رایگان اولیهای در نظر گرفته که امکان پردازش تا ۱۰۰ صفحه را بدون پرداخت هزینه فراهم میکند. پس از آن، قیمتگذاری بهصورت مصرفمحور (Pay-as-you-go) انجام میشود، بهطوریکه کاربران فقط به ازای تعداد صفحات یا API callهای پردازششده پرداخت میکنند. این مدل بهویژه برای استارتاپها، پروژههای آزمایشی و کسبوکارهای مقیاسپذیر بهینه است.
کاملاً بله. یکی از کاربردهای اصلی OCR در ایران و جهان، استفاده در احراز هویت دیجیتال (KYC) است. اطلاعات استخراجشده از کارت ملی، شناسنامه یا قبض توسط OCR بهصورت ساختیافته پردازش میشود و سپس از طریق سامانههای رسمی مانند ثبتاحوال، شاهکار یا بانک مرکزی، بهصورت لحظهای تطبیق داده میشود. این یکپارچگی باعث کاهش خطای انسانی، تسریع روند ثبتنام و افزایش امنیت و انطباق قانونی میشود.